
2 years, 1 month ago
SUS 2023/2024 Second Project
This is the second project for students enrolled in the Machine Learning 2022/2023 course (Systemy Uczące Się - SUS) at the Faculty of Mathematics, Informatics, and Mechanics at the University of Warsaw.
The goal of this competition is to build a prediction model that is capable of deciding whether two images - one original and the other encoded (scrambled) - are indeed the same thing or not. This problem originates from the attempt to secure monitoring devices and make them compliant with GDPR.
Competition rules are given in Terms and Conditions.
The description of the task, data, and evaluation metric is in the Task description section.
The deadline for submitting solutions is June 14, 2024.
This task is associated with the idea of building systems for collecting and analyzing data from the environment. With the use of proprietary devices consisting of a set of optical sensors, it is possible to collect information about people moving nearby, including: movement direction, interest analysis, and demographic profile. Then, with the use of AI/ML algorithms, it is possible to interpret the collected information and provide the profile of an audience within the range of the devices, e.g. by recognizing their age and gender.
One of the very important challenges for such devices is the preservation of privacy and protection of personal information (e.g., name, gender, age, location) of the persons being monitored. In order to meet the legal requirements, such as those established in the EU's General Data Protection Regulation (GDPR), monitoring systems (platforms) are intended to use strong encryption and anonymization techniques. These anonymization and privacy-preservation methods have to be robust and safe.
The task for this project is to check sufficiency of the level of encryption/anonymization used in the monitoring systems. We provide the challenge participants with a (training) set of examples consisting of the original image (taken from the public domain) and its encoded (scrambled) version. Then, on a separate set of pairs (test/verification set), the participants have to decide (Yes/No) whether the scrambled file contains the visible image or not. If it is possible to train a model that would make such a decision with high accuracy, it will be a proof-by-example that the encoding techniques used need improvement. However, the task corresponds to the encryption that takes place inside the monitoring system. This type of data would not be possible to obtain without physical access to the monitoring device.
Task
Given the pair of images, one original and one after encoding, determine (Yes/No - 0/1) whether they are the same or not. The encoded image is a result of applying an image obfuscation scheme based on the chaotic system theory. In these algorithms, the original image is an argument for parameterized chaotic mapping, in this case, Arnold’s cat map (cf. [1]). The chaotic systems are characteristic of significant changes in output caused by even tiny changes in their input. Hence, their application in image content protection (cf. [2]). The original images collected from the public domain are first adjusted, using cropping, padding, and scaling, to a square measuring 512 by 512 pixels. Then, the picture is divided into 32-by-32-pixel tiles. The tiles are individually encoded with the use of Arnold’s cat map and form the final encoded image.
An example of the original and encoded picture:

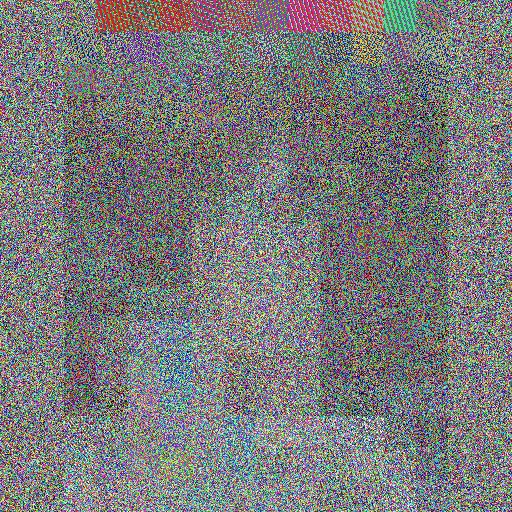
Submission format: The participants are required to submit a text file containing exactly 10000 lines containing binary predictions for the test part of the data in the order corresponding to the image identifiers. Just one number (0/1) per line.
Evaluation: Since the answers (predictions) are binary (0/1), the evaluation will be done with accuracy measure (ratio of correct predictions).
The number presented on the leaderboard will be calculated as:
Acc = (TP+TN)/N
where TP stands for True Positive, TN for True Negative, and N=10000 for the size of data set.
The preliminary evaluation is done on a small fraction of the test cases. This number is then displayed on the Leaderboard. For the final evaluation, the accuracy will be calculated on the remaining part of the test data set. Hence, Leaderboard results are only an estimation of the true error. Remember, that if the method/algorithm/model is overfitted this estimation may turn out to be unreliable.
Data set
The data set can be downloaded from Google Drive as a single, compressed (zip) archive - data.zip (7,18 GB)
https://drive.google.com/file/d/1B2WRPZaIlqClJY9MDd0vhbfBbv1H6npr/view?usp=sharing
The dataset contains 10000 training image pairs and 10000 test image pairs - 40000 JPG images alltogether. All images are 512 by 512 pixels. They are arranged into directiories as follows:
| -- train | | | -- input - 10000 original train images | | | -- enc - 10000 encoded train images -- test | | | -- input - 10000 original test images | | | -- enc - 10000 encoded test images
both train and test folders contain also a comma separated value (.csv) file listing the paths to each pair of train/test images.
Additional information
This dataset is taken from one of three sub-tasks in the IEEE BigData 2022 Cup: Privacy-preserving Matching of Encrypted Images. The description of this competition and its results can be forund in the report [3]. Additionanlly, description of winning solutions can be found in [4-7].
References to resources mentioned in the task description:
- Wikipedia - the free Encyclopedia: Arnold’s cat map. https://en.wikipedia.org/wiki/Arnold's_cat_map
- Z.-H. Guan, F. Huang, W. Guan: Chaos-based image encryption algorithm. Physics Letters A, Vol. 346, Issues 1-3, 2005, pp. 153-157 https://doi.org/10.1016/j.physleta.2005.08.006.
- IEEE BigData Cup 2022 Report: Privacy-preserving Matching of Encrypted Images
Marcin Szczuka, Andrzej Janusz, Bogusław Cyganek, Jakub Grabek, Łukasz Przebinda, Andżelika Zalewska, Andrzej Bukała and Dominik Ślęzak
Proceedings of 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, December 17-20, 2022, Page 6453. DOI: 10.1109/BigData55660.2022.10020599 -
Identification of Encrypted Images Based on Image Statistics (Page 6436)
Stanisław Kaźmierczak -
Demystify scrambled and encoded images with auto-encoders (Page 6442)
Huu-thanh Nguyen, Quang Hieu Vu and Anh-dung Huynh -
Gradient Boosted Trees for Privacy-Preserving Matching of Encrypted Images (Page 6448)
Jakub Pokrywka -
IEEE Big Data Cup 2022: Privacy Preserving Matching of Encrypted Images with Deep Learning (Page 6463)
Vrizlynn L. L. Thing
| Rank | Team Name | Score | Submission Date |
|---|---|---|---|
| 1 | skibarch |
1.0000 | 2023-05-30 17:54:36 |
| 2 | @@@ |
1.0000 | 2023-05-31 18:58:52 |
| 3 | team_1 |
0.9980 | 2023-05-29 15:13:22 |
| 4 | gasior |
0.9980 | 2023-05-31 15:09:15 |
| 5 | Haponiuk |
0.9980 | 2023-06-1 13:01:41 |
| 6 | machine_learner |
0.9970 | 2023-05-31 19:52:39 |
| 7 | AM |
0.9950 | 2023-05-30 21:36:19 |
| 8 | Jacek |
0.9910 | 2024-06-7 10:17:07 |
| 9 | Jakub Zarzycki |
0.9890 | 2023-05-31 21:58:26 |
| 10 | SUS2023 |
0.9830 | 2023-05-31 09:42:35 |
| 11 | zsw |
0.9710 | 2023-06-1 02:05:08 |
| 12 | iStrzalka |
0.9690 | 2023-05-17 17:09:48 |
| 13 | MM |
0.9650 | 2023-05-24 12:49:02 |
| 14 | Stanisław_Durka_SUS |
0.9400 | 2023-05-31 19:49:24 |
| 15 | MK |
0.9390 | 2023-05-30 17:36:54 |
| 16 | team_rocket |
0.9110 | 2023-05-31 18:13:08 |
| 17 | Maria_Paczkowska |
0.7730 | 2023-05-31 21:47:59 |
| 18 | baseline_solution |
0.7090 | 2023-05-28 03:15:44 |
| 19 | Marcin |
0.5120 | 2023-05-31 21:04:38 |
- May 1, 2023 - project starts, the competition goes online and participants can start submitting solutions.
- May 31, 2023 - project ends. Deadline for selection of final solution and submission of report/code.
- June 10, 2023 - final deadline for overdue final solutions and/or reports/code.
The second project will be scored on the scale between 0 and 30 course points.
The students are scored on the basis of the final result published on the Leaderboard. This final result will be calculated as accuracy calculated on the part of the test data that was not used for calculating preliminary results presented on the Leaderboard during the competition. The participants will be required to select one of the submitted solutions as final, and this solution will then undergo final evaluation.
Additionally, the quality of the submitted short report and code will be taken into consideration. A significant percentage of points may be deduced from the score if they raise any eyebrows.
The final score will be established using a procedure as follows:
- +20 pts. for surpassing the baseline, i.e., for obtaning a final result that is placed on the Leaderboard above the final baseline solution.
- up to +10 pts. for the position on the final Leaderboard, provided pt. 1 above is fulfilled. This part of the score will be relative to the composition of the final Leaderboard. Top solution gets +10 pts. bottom one (but still above baseline) gets +1 pt. Solutions with final accuracy above 0.95 are automatically given +10 points.
- down to 10 pts. for the position on the final Leaderboard if the final solution is below the final baseline by more than 5 pecentage points. Again, this part of the score will be relative to the composition of the final Leaderboard. Top solution gets 15 pts. bottom one (worst overall) gets a score of 10 pt.
- 10% of the score established above (1-3) will be deduced for every day of delay in submitting final solution, report and code. The deadline for timely solution submission is May 31 (23:59).
Warning: It is not sufficient to send a random solution to score 10 points. As mentioned above, the quality of report and code will also be scrutinised.
This forum is for all users to discuss matters related to the competition and course project. Good manners apply!
With individual questions you may contact Dr Marcin Szczuka (szczuka@mimuw.edu.pl), but the Forum is a preferred mode of communication.
| Discussion | Author | Replies | Last post | |
|---|---|---|---|---|
| Kod źródłowy rozwiązania / Solution source code | Marcin | 0 | by Marcin Thursday, June 01, 2023, 07:15:35 |
|
| UWAGA|WARNING: Bład w funkcji ewaluacji. Error in evaluation function | Marcin | 1 | by Marcin Sunday, May 28, 2023, 11:44:43 |
